Chapitre 2 La qualité de service
dans l'Internet
2.1 Introduction du chapitre
L'Internet est un réseau à commutation de paquets à l'architecture et aux
principes simples, qui ne fournit qu'un service dit ``au mieux''
(best-effort) c'est à dire sans aucune garantie sur le débit
disponible, le délai subi ou encore les pertes de paquets. Ce service
s'avère suffisant pour les applications ``élastiques'' de transfert de
données telles que courrier électronique, groupes de discussion, transfert
de fichiers etc1.
Avec le développement considérable de l'Internet, de nouveaux usages se
développent autour d'applications multimédias dont les contraintes temps
réel se satisfont difficilement du service au mieux. Certaines de ces
applications peuvent être conçues de manière à fonctionner plus ou moins
bien avec un tel service minimal, mais ces applications adaptatives
ont cependant besoin d'un minimum de conditions pour se comporter
correctement. De plus, certaines applications ont des contraintes fortes et
ne peuvent pas s'adapter.
On dira qu'un réseau peut fournir de la qualité de service
(QoS pour Quality of Service) s'il est capable de fournir un
service adapté aux besoins spécifiques des applications (en particulier
temps réel) : garantie de débit ou de délai par exemple.
Dans le cadre de l'Internet, deux architectures basées sur des paradigmes
différents ont été développées par l'IETF2 pour fournir la qualité de service. Ces deux architectures, bien que
très différentes, utilisent un certain nombre d'élements de base communs.
Dans ce chapitre, nous décrivons les deux architectures envisagées pour
fournir la qualité de service dans un réseau à commutation de paquets tel
que l'Internet. Nous rappelons ensuite comment il est possible d'obtenir des
garanties de délai déterministes.
Puis nous décrivons l'élément fondamental sur lequel doit s'appuyer toute
architecture destinée à fournir la qualité de service, l'ordonnancement de
paquets en étudiant le cas des algorithmes de la famille
weighted fair queueing.
2.2 Le modèle IntServ/RSVP
Le groupe de travail ``Integrated Services''
(IntServ3)
de l'IETF a été créé en 1994 pour définir un modèle de service de l'Internet
amélioré, capable de transporter aussi bien de l'audio, de la vidéo, des
données temps réel que du trafic de données classique ; c'est à dire
transformer l'Internet en un réseau à intégration de services.
Le travail du groupe (tel que spécifié dans sa charte) se décompose en trois
parts :
- définir les services ;
- définir les interfaces aux applications, aux mécanismes des routeurs
et aux technologies réseaux sous-jacentes (uniquement les interfaces
générales dans ce dernier cas, les détails spécifiques à chaque
technologie devant être traités par le groupe ISSLL4) ;
- développer des mécanismes de validation certifiant la conformité des
routeurs aux exigences du nouveau modèle (l'idée étant de ne pas imposer
une implémentation particulière -- e.g. un algorithme d'ordonnancement --
mais de spécifier le comportement).
L'architecture globale du modèle IntServ était définie dans ses grandes
lignes dès 1994 dans le RFC 1633 [BCS94] dont la partie modèle de
service est très largement inspirée de [CSZ92]. Il s'agit donc d'un
travail longuement mûri.
Nous décrivons ci-dessous l'architecture globale du modèle, les services
proposés, la caractérisation des flots utilisée et le protocole de
signalisation. Nous concluons par une discussion des limitations du modèle
en terme de scalabilité.
2.2.1 Architecture
On définit un flot comme étant une suite identifiable de paquets apparentés
qui résultent de l'activité d'un utilisateur et ont besoin de la même
qualité de service.
La qualité du service fourni par le réseau à un flot dépend des ressources
(bande passante et tampons mémoire) disponibles. Pour garantir une qualité
de service à un flot, il faut s'assurer qu'une quantité de ressources
suffisante est disponible dans chacun des routeurs (et liens) qu'il traverse
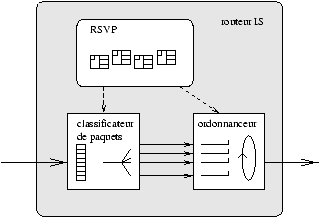
pendant toute la durée du flot. Comme le montre la figure 2.1,
dans chaque routeur on appelle ``contrôle de trafic'' (traffic
control) l'ensemble des éléments qui permettent d'assurer cette condition,
au nombre de trois :
-
le classificateur de paquets
- détermine à quel flot appartient un
paquet,
- l'ordonnanceur de paquets
- sélectionne pour émission les paquets des
différents flots en fonction des ressources réservées,
- le contrôle d'admission
- vérifie que suffisamment de ressources sont
disponibles au moment de l'établissement de la réservation.
Figure 2.1 : Routeur à intégration de services
Le quatrième élement fondamental d'un réseau à intégration de services est
le protocole de mise en place de réservation qui à partir de la
requête formulée par une application fournit les informations au contrôle de
trafic de chaque routeur appartenant au chemin du flot et récupère la
réponse du module de contrôle d'admission. Le protocole choisi pour IntServ
est RSVP (Resource reSerVation setup Protocol) que nous décrivons brièvement
en 2.2.4.
2.2.2 Classes de services
Plusieurs classes de services ont été discutées par le groupe de travail
IntServ depuis sa création. Seules deux propositions ont finalement été
retenues et sont arrivées à maturité, mais rien n'exclut (en principe) la
proposition de nouveaux services.
- Controlled Load (CL) :
- la classe à charge contrôlée
[Wro97a] fournit le même service qu'un réseau best-effort en
situation non congestionnée, ce qui est un peu flou. Cette classe est
destinée tout particulièrement aux applications multimédias adaptatives
dont l'usage s'est développé ces dernières années. Il a en effet été
constaté que ces applications se comportent remarquablement bien avec un
service best-effort, s'adaptant aux variations et aléas du service
tant que le réseau n'est pas dans une situation de congestion critique,
auquel cas leur comportement se dégrade très rapidement.
- Guaranteed Service (GS) :
- la classe à service garanti
[SPG97] fournit une garantie stricte sur le délai maximum de chaque
paquet et assure un taux de perte nul. Elle s'adresse aux applications
temps réel non adaptatives. Nous décrivons en 2.4 les
fondements théoriques sur lesquels se base un tel service.
2.2.3 Caractérisation des flots
Dans l'architecture IntServ, chaque flot est caractérisé par un TSPEC
(traffic specification) [SW97] qui comprend les cinq
paramètres décrits dans le tableau 2.1.
| Paramètre |
Description |
| b |
Taille maximum de rafale |
| r |
Débit moyen |
| p |
Débit crête |
| L (ou M) |
Taille maximum de paquet |
| m |
Plus petite unité de poliçage |
Table 2.1 : Les paramètres de spécification de trafic
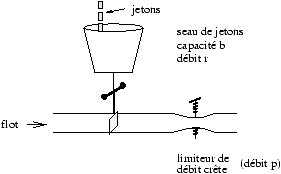
Les paramètres les plus importants sont les trois premiers, ils permettent
de caractériser le flot selon un modèle constitué d'un seau de
jetons5 (token bucket) qui
contrôle le débit moyen et la taille de rafale, suivi d'un limiteur de débit
crête. Ceci est illustré par la figure 2.2.
Figure 2.2 : Caractérisation d'un flot
Les deux autres paramètres sont secondaires (mais pas superflus), dans le
sens où ils ne caractérisent le flot que par rapport à l'implémentation des
mécanismes de qualité de service. La QoS n'est garantie qu'aux paquets dont
la taille ne dépasse pas la taille maximum de paquet spécifiée dans
le TSPEC. Tout paquet dont la taille est inférieure à la plus petite
unité de poliçage sera ``facturé'' comme ayant cette
taille6. Les ressources
à réserver dans le réseau dépendent bien entendu, pour une qualité de
service donnée, de cette caractérisation.
Ce type de caractérisation a l'avantage d'être assez simple à comprendre et
à manipuler. Il n'est cependant pas adapté à tous les types d'applications
(e.g. une application qui génère un flot à débit constant avec de grandes
rafales très espacées).
2.2.4 La signalisation : RSVP
Caractéristiques
Le protocole RSVP [ZDE+93] (Resource reSerVation setup
Protocol) a été défini par le groupe de travail
RSVP7
(sic) de l'IETF [BZB+97]. La flexibilité et la capacité à gérer des
sessions entre un grand nombre de participants ont été les objectifs
principaux dans la conception de RSVP, comme le montrent les
caractéristiques suivantes :
-
Multipoint N vers M :
- gestion de la QoS pour des sessions multipoint
à multipoint (la session point à point classique étant un cas
particulier).
- Hétérogénéité :
- différents récepteurs d'un même flot peuvent recevoir
une QoS différente. Pour cela le protocole est :
- Orienté récepteur :
- ce sont les récepteurs qui choisissent la qualité
de service à fournir au flot.
- Dynamicité :
- les réservations sont renégociables à tout moment, la
composition des groupes est totalement dynamique et les changements de
route sont possibles.
- États relachés :
- l'état maintenu dans les routeurs est
``relaché'' (soft state) : il doit être rafraîchi régulièrement pour
ne pas disparaître.
- Réservations partagées :
- possibilité de partager les réservations
entre plusieurs flots (émetteurs) de la même session selon différentes
modalités (utile par exemple dans le cas d'une audioconférence où un seul
des participants parle -- émet -- à tout instant).
Mécanismes
Nous décrivons maintenant brièvement les mécanismes de RSVP.
Une session RSVP est identifiée par une adresse IP destination
(éventuellement multicast) et un numéro de session. Plusieurs flots peuvent
exister dans la même session, un par émetteur. Une application désirant
participer en tant qu'émetteur dans cette session envoie des messages PATH
contenant le TSPEC du flot qui sont routés jusqu'au(x) destinataire(s).
Dans le cas d'une session multicast, les récepteurs ont simplement adhéré
préalablement au groupe IP multicast correspondant. Dans chacun des routeurs
qu'ils traversent, ces messages PATH créent un Path State contenant
essentiellement l'adresse du routeur précédent (Previous Hop), créant
ainsi un arbre de parcours inverse. Chaque routeur ajoute
également au message PATH des informations, contenues dans les objets ADSPEC
(advertising specification), sur les qualités de service qu'il est
capable de fournir, ce qui correspond à un mécanisme ``une passe avec
collecte'' (one pass with advertising ou OPWA). Un appel à la
fonction de routage permet ensuite de déterminer le lien de sortie à
utiliser pour envoyer le message vers le noeud suivant.
Quand une application réceptrice reçoit le message PATH, elle connaît alors
les caractéristiques du flot de données proposé et celles du chemin
parcouru. Elle spécifie la qualité de service qu'elle désire obtenir en
envoyant un message RESV qui ``remontera'' vers l'émetteur grâce aux
Path States installés par le message PATH. Ce message RESV contient
le ``TSPEC du récepteur'' caractérisant le trafic pour lequel le récepteur
veut réserver des ressources (dans le modèle théorique un récepteur peut
réserver des ressources pour un sous-flot) et un RSPEC
(resource specification) spécifiant les ressources à réserver. À
chaque noeud, un contrôle d'admission est réalisé pour vérifier que
suffisamment de ressources sont disponibles pour fournir le service
demandé. Si c'est le cas, un Resv State est créé, contenant les
informations relatives à la réservation à effectuer et le message est envoyé
au noeud amont. Les Resv States créés par différents récepteurs (de
la même session) et associés au même lien de sortie sont accumulés dans un
Traffic Control State contenant la réservation globale sur ce lien
pour cette session. Les états de classification et d'ordonnancement peuvent
alors être mis en place.
Tous les états étant relachés (soft states), les messages sont reémis
périodiquement pour les rafraîchir. Cela permet également, en association
avec les mécanismes d'IP multicast, à de nouveaux participants de se joindre
à la session dynamiquement. De plus les états ``orphelins'' ne resteront pas
indéfiniment dans le réseau. L'effacement des états se fait normalement de
manière explicite avec les messages PTEAR (path tear) et RTEAR
(resv tear) mais l'effacement d'un soft state à l'expiration
d'un temporisateur de survie (cleanup timeout) permet
d'assurer la robustesse du protocole sans nécessiter la fiabilité de la
transmission des messages.
La spécification complète de RSVP, donnée dans [BZB+97], est assez
complexe (112 pages). Elle contient également la définition des interfaces
avec les applications et les routeurs. Une implémentation de l'interface
avec l'application, nommée RAPI (RSVP Application Programming
Interface) est décrite dans [BH97]. Le RFC ``RSVP Message Processing
Rules'' [BZ97] contient une description algorithmique des règles que
doit utiliser une implémentation de RSVP et est destiné à clarifier la
spécification.
Utilisation avec IntServ
RSVP n'est pas lié aux classes de service de l'IntServ et peut être utilisé
dans d'autres contextes. De nouvelles classes peuvent d'ailleurs
théoriquement être ajoutées à l'architecture IntServ. Sa spécification ne
décrit donc pas la sémantique des informations qu'il transporte. Au
contraire, les objets transportés par RSVP sont ``opaques''. [Wro97b]
(``The Use of RSVP with IETF Integrated Services'') décrit le format et les
règles de traitement des objets à utiliser pour les classes de service CL et
GS.
Sécurité et contrôle d'accès
Dans un environnement non contrôlé, des techniques de sécurité sont
nécessaires pour empêcher le ``vol'' de ressources et le sabotage de
connexions. L'utilisation de méthodes d'authentification cryptographiques
est proposée dans [BLT99].
De même, des règles de contrôle (policy control) doivent être
définies pour vérifier qui effectue une réservation (authentification de
l'utilisateur, comptabilité). Ceci est le rôle du groupe de travail
RAP8 pour
RSVP Admission Policy, récemment renommé en Resource
Allocation Protocol. Ce domaine est encore l'objet de recherches.
2.2.5 Scalabilité
Le reproche majeur couramment fait à IntServ, et probablement le facteur
principal retardant (empêchant ?) son déploiement est la difficulté liée au
passage à l'échelle. En effet le paradigme utilisé, la gestion des
ressources par flot, implique de maintenir dans chaque routeur un
triple état pour chaque flot traversant ce routeur (indépendament d'autres
états globaux qui ne posent pas de problème d'échelle) :
-
signalisation :
- état de contrôle (par exemple les resv et
path states de RSVP).
- classification :
- pour l'identification des paquets d'un flot.
- ordonnancement :
- pour l'allocation des ressources réservées.
Figure 2.3 : Un état par flot dans chacun des trois modules
La gestion d'états par flot ne pose pas de problème dans un
environnement de taille réduite où le nombre de flots est limité. Cependant
IntServ a pour vocation d'être déployé à l'échelle de l'Internet, donc en
particulier dans les réseaux d'interconnexion (les backbones) qui
peuvent être traversés par plusieurs centaines de milliers de flots de
données. Cette situation ne peut qu'empirer avec l'accroissement régulier de
la taille de l'Internet. En ce qui concerne l'aspect signalisation, l'IETF a
édité un ``constat d'applicabilité'' de RSVP [M+97] qui incite à la
prudence quant au déploiement à grande échelle de RSVP, mettant en lumière
les problèmes potentiels en scalabilité mais aussi en sécurité et contrôle
d'accès (que nous avons évoqués plus haut).
Il est difficile de dire dans quelle mesure et à partir de combien de flots
la gestion d'état par flot devient impossible. L'opération de classification
peut se réduire à la lecture d'un champ d'en-tête et à une indirection grâce
à cette valeur dans un tableau des réservations, opérations qui peuvent
certainement être cablées. Beaucoup de recherches sont également menées pour
cabler des algorithmes d'ordonnancement [RGB96, VS97].
Les états de signalisation maintenus par RSVP sont eux beaucoup plus
complexes et ne se prêtent donc pas à une implémentation cablée. Étant
cependant situés dans le plan de contrôle, ils sont utilisés beaucoup moins
intensément. [Gué98] donne quelques valeurs de la charge engendrée
par la gestion des états de RSVP. Au chapitre 3, nous étudions cet
aspect dans le cadre de l'évaluation de notre proposition ``RSVP
switching'', section 3.4.3, page ??.
2.3 Le modèle DiffServ
En réaction aux limites et aux difficultés de déploiement du modèle IntServ,
et face aux demandes de plus en plus pressantes des fournisseurs d'accès qui
veulent pouvoir proposer différents types de service, un nouveau groupe de
travail de l'IETF, The Differentiated Services Working Group ou
DiffServ9,
a été chargé d'étudier une nouvelle approche, appelée la
différenciation de services. Le modèle DiffServ suscite beaucoup de
travail, mais certains documents de référence ne sont pas encore finalisés.
Nous présentons ci-dessous ses principes, son architecture, et les types de
services proposés.
2.3.1 La différenciation de services
``An Architecture for Differentiated Services'' [B+98] définit un
service comme :
...un ensemble de caractéristiques de transmission de paquet
exprimées quantitativement ou statistiquement en termes de débit, délai,
gigue et/ou taux de perte ou en terme de priorité relative d'accès aux
ressources du réseau.
Comme on le voit cette définition est assez lâche et se différencie
nettement du concept de qualité de service utilisé par IntServ. DiffServ
fournit en fait un ensemble de briques (building blocks) qui peuvent
être utilisées pour construire différents types de service.
Le but affiché, similaire à celui d'IntServ, est de satisfaire des besoins
d'applications et des attentes d'utilisateurs hétérogènes, mais l'approche
utilisée est très différente.
2.3.2 Architecture
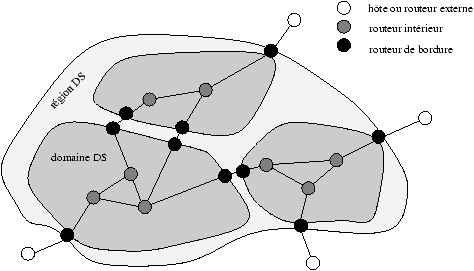
Le principe du modèle à différenciation de services est de séparer le trafic
en quelques classes de trafic (agrégats de flots applicatifs appelés
micro-flots) identifiées par une valeur codée dans l'en-tête de
chaque paquet IP [NBBB98]. Cette opération de classification est
opérée à l'entrée du réseau (ou de la zone où la différenciation de service
est mise en oeuvre -- domaine DS) par les noeuds de
bordure (boundary nodes) qui gèrent des états par flot. Les
noeuds intérieurs (interior nodes) ne gèrent que des états
par classe et traitent les paquets en fonction de la classe codée dans
l'en-tête en les traitant en accord avec le comportement local
(per hop behavior ou PHB) correspondant. Le service perçu de
bout en bout pour un PHB dépend de la politique de provisionnement du
réseau pour chaque PHB et du conditionnement de trafic effectué
dans les noeuds de bordure.
Un domaine DS est une zone administrative fournissant la
différenciation de services, c'est à dire fonctionnant avec un ensemble
commun de politiques de provisionnement du réseau et de définitions de PHBs.
Une région DS est un ensemble contigu de domaines DS qui peuvent
offrir la différenciation de services sur des chemins traversant ces
domaines. Ils ne mettent évidemment pas forcément en oeuvre les mêmes
politiques de provisionnement ni les mêmes PHBs.
Figure 2.4 : L'architecture DiffServ
Les détails de l'architecture sont définis dans [B+98] et
[BBB+99], un modèle pour les routeurs supportant DiffServ
est donné dans [BSB99].
2.3.3 Per hop behaviors
Deux per hop behaviors (PHBs) ont été définis. Ce sont
expedited forwarding (EF) et assured forwarding (AF).
Expedited forwarding
Le PHB expedited forwarding (traitement accéléré) [J+99] a
pour but de fournir une garantie de bande passante avec des taux de perte,
délai et gigue faibles, soit un service pouvant s'apparenter à une ``ligne
louée virtuelle''. Aux débuts du travail sur DiffServ, ce service avait été
proposé sous le nom Premium Service.
La spécification du PHB indique qu'à tout moment, le débit instantané
(calculé sur un intervalle de temps égal à la durée d'émission, au débit
configuré, d'un paquet de taille maximum) alloué à cette classe de trafic
doit être supérieur au débit configuré. Ce qui implique de :
-
configurer de manière appropriée le débit alloué dans les noeuds,
- conditionner le trafic à l'entrée du domaine de façon que le débit
d'arrivée à chaque noeud soit inférieur au débit alloué.
Le rôle du PHB se limite au premier point, le deuxième dépendant de
techniques de provisionnement du réseau.
Ce PHB est un bon candidat pour construire un service de même type que le
service GS d'IntServ. Cependant, Stoica et Zhang ont montré dans
[SZ98] qu'il n'est possible d'obtenir des délais faibles que si un
pourcentage réduit du trafic utilise ce PHB. De plus aucune méthode n'est
proposée pour assurer le point 2 de manière efficace.
Assured forwarding
Il s'agit en fait non d'un PHB mais d'une famille de PHBs (PHB
group). Quatre classes de ``traitement assuré'' sont définies, chacune
comprenant trois niveaux de priorité spatiale (drop precedence)
[H+99]. Dans un noeud donné, le niveau d'assurance de traitement
d'un paquet dépend de la bande passante allouée à la classe, de la charge
actuelle de la classe et de la priorité spatiale du paquet. La nature de la
différence entre les classes n'est pas spécifiée, mais elle est souvent
pensée en terme de délais [MF98].
Chaque noeud doit mettre en oeuvre des mécanismes visant à :
-
réduire la congestion de long terme dans la classe,
- accepter les rafales (congestion à court terme),
- traiter identiquement les micro-flots ayant des débits moyens
identiques (i.e. ne pas défavoriser un micro-flot bursty).
Ceci implique la mise en oeuvre d'un algorithme de gestion active de la
file, du type RED (Random Early Detection)
[FJ93, FF97, Del00].
Le service fourni par chaque classe peut être modulé par le réglage des
paramètres de cet algorithme en conjonction avec ceux du conditionnement de
trafic opéré aux noeuds de bordure. Des ``marqueurs à trois couleurs''
sont proposés [HG99a, HG99b] pour diviser le trafic de
chaque classe selon les trois priorités.
2.3.4 Avantages et problèmes
En séparant le trafic en un nombre réduit de classes et en repoussant la
complexité (classification et conditionnement) aux extrémités du réseau, ce
modèle atteint l'objectif de scalabilité pour le plan de données. Par
contre, par rapport à IntServ il est clair que l'on perd soit en flexibilité
soit en fermeté des garanties. De plus, à moins de se contenter d'une forte
sous utilisation du réseau (i.e. conditionner le trafic de manière très
conservatrice), le problème du plan de contrôle reste entier. Dans le cas de
trafic multicast, les choses se compliquent encore et aucune approche n'est
proposée sur la façon de dimensionner le réseau et de conditionner ce type
de trafic. Clairement, le groupe de travail se trouve confronté sur ce point
à des problèmes très difficiles à résoudre.
2.4 Les garanties de délai
Émulation de canal
La classe de service Guaranteed Service est conçue pour fournir aux
applications une garantie stricte sur le délai subi par chaque paquet d'un
flot pendant qu'il traverse les noeuds du réseau. Ce délai est composé de
deux parts, le temps de propagation lié au support physique et
incompressible, et le temps passé dans les files d'attente, que l'on peut
contrôler par divers mécanismes. Nous nous intéressons ici uniquement au
temps passé dans les files d'attente, le temps de propagation pouvant être
facilement calculé et ajouté pour obtenir un délai total.
Pour fournir une garantie de délai, il faut isoler complètement le flot des
autres flots de données en lui fournissant un canal de communication
dédié à l'intérieur de chaque lien qu'il traverse. L'émulation parfaite de
ce canal, dans laquelle le flot se voit attribuer une part de bande passante
est appelée le modèle fluide. Dans un réseau à commutation de
paquets les noeuds ne peuvent fournir qu'une approximation du service
fourni par le canal dédié. Dans chaque noeud, la déviation entre le modèle
fluide et cette approximation peut se caractériser par deux termes d'erreur
que l'on définit de la manière suivante :
-
C
- est le terme d'erreur dépendant du débit. Il sert à calculer le
délai potentiel maximum ajouté à un paquet lié aux paramètres de
caractérisation du flot10. Il est exprimé
en octets (ou bits) et est divisé par la réservation affectée au flot pour
obtenir le délai correspondant.
- D
- est le terme d'erreur indépendant du débit. Il représente la plus
grande variation de délai (indépendante du débit du flot) qu'un paquet
peut subir dans le noeud. Un délai constant ajouté systématiquement sera
plutôt considéré comme faisant partie du délai de propagation.
Les valeurs de ces termes d'erreur dépendent de la façon dont est réalisée
l'approximation du canal du modèle fluide, c'est à dire de l'ordonnanceur
mis en oeuvre dans le noeud. Nous donnons ces valeurs dans le cas d'un
ordonnanceur de type weighted fair queueing (WFQ) en 2.5.
Utilisation des courbes d'arrivée et de service
La courbe d'arrivée maximale (dans un modèle abstrait fluide -- non
paquétisé) d'un flot caractérisé par le TSPEC (b, r, p) (défini section
2.2.3 page ??) et ayant L comme
taille maximum de paquet est [PG93, G+96] :
A(t) = min{ p.t, b + r.t }
ce qui s'explique de la manière suivante. À long terme (t grand) le
service maximum est obtenu quand le flot a émis une rafale de taille maximum
(b) et continue d'émettre à son débit moyen (r). Ceci est exprimé par le
terme b+r.t. Cependant, la rafale ne peut pas être émise
instantanément, le débit étant limité par le débit crête (p). Ainsi, si à
partir de t=0 la source émet une rafale, elle pourra émettre à son
débit crête jusqu'à ce que la taille maximum de rafale ait été atteinte,
après quoi elle devra se limiter à son débit moyen. Donc, pour t petit,
la courbe serait p.t.
Il faut cependant tenir compte du fait que le flot n'est pas fluide mais
constitué de paquets. Quel que soit le lissage mis en oeuvre, un paquet
est toujours émis au débit du lien, qui peut être beaucoup plus important
que le débit crête du flot. N'ayant aucun moyen de le connaître en général,
nous sommes forcés de le considérer comme infini. Ainsi, la courbe d'arrivée
du flot pour des valeurs de t petites devient L + p.t, ce qui
correspond à une augmentation de l'effet des rafales.
A(t) = min{ L + p.t, b + r.t }
Voyons maintenant la courbe de service minimale garantie par le réseau. Pour
prendre en compte les termes d'erreur Ci et Di de chaque noeud on
peut considérer que l'ensemble forme un seul système caractérisé par les
termes åCi et åDi. Le service offert dans le pire des cas est
alors l'ajout d'un délai å(Ci/R + Di), puis la fourniture
d'un débit constant et égal à la réservation effectuée R.
La figure 2.5 montre comment ces deux courbes peuvent être
utilisées pour calculer le délai maximum subi par un paquet (délai d'attente
dans les queues, n'incluant pas le délai de propagation) et la taille
maximum des tampons nécessaires dans un noeud du réseau.
Figure 2.5 : Courbes d'arrivée et de service
Calcul du délai
Le segment IJ représente le délai maximum. Calculons sa longueur. On a (n
étant le nombre de noeuds traversés) :
| yI = L+p xI = b + r xI Þ xI = |
|
et :
| xJ = |
|
+ |
|
|
æ
ç
ç
è |
|
+ Di |
ö
÷
÷
ø |
La longueur du segment est donc :
| D = xJ - xI = |
|
- |
|
+ |
|
|
æ
ç
ç
è |
|
+ Di |
ö
÷
÷
ø |
Comme yI et yJ sont égaux, remplaçons yJ par
L+p · b-L/p-r :
| D = |
|
- |
|
+
|
|
|
æ
ç
ç
è |
|
+ Di |
ö
÷
÷
ø |
| D = |
|
+ |
|
· |
|
- |
|
+
|
|
|
æ
ç
ç
è |
|
+ Di |
ö
÷
÷
ø |
| D = |
|
· |
æ
ç
ç
è |
|
-1 |
ö
÷
÷
ø |
+ |
|
+
|
|
|
æ
ç
ç
è |
|
+ Di |
ö
÷
÷
ø |
| D = |
|
· |
|
+ |
|
+
|
|
|
æ
ç
ç
è |
|
+ Di |
ö
÷
÷
ø |
ce qui nous donne finalement :
|
D =
|
|
· |
|
+ |
|
+
|
|
|
æ
ç
ç
è |
|
+ Di |
ö
÷
÷
ø |
(2.1) |
Bien entendu, cette équation n'est valable que si la réservation R est
supérieure au débit moyen du flot (condition de stabilité R > r). Nous
nous sommes de plus placés dans le cas où p > R. Dans le cas contraire
(p<R), les calculs sont beaucoup plus simples et la formule
(2.1) devient :
|
D =
|
|
+ |
|
|
æ
ç
ç
è |
|
+ Di |
ö
÷
÷
ø |
(2.2) |
Qu'elle soit sous sa forme (2.1) ou (2.2),
cette formule est composée de deux termes :
- un terme ``d'écoulement de rafale'' représentant le délai nécessaire
pour écouler (c'est à dire lisser) une rafale de taille maximum au débit
réservé. Dans le cas où la réservation est supérieure au débit crête ce
terme se réduit à L/R, correspondant à une rafale d'un paquet
émis à un débit infini.
- un terme ``d'approximation du modèle fluide'' constitué par la somme
des délais potentiels ajoutés à chaque noeud du fait des erreurs
d'approximation du canal fluide.
La réservation allouée au flot joue sur chacun des deux termes. Les autres
paramètres que l'application peut utiliser sont pour le premier terme la
variabilité du trafic qu'elle génère. Pour le deuxième, cela dépend de la
valeur du terme C donc de la politique d'ordonnancement mise en oeuvre.
Calcul de la réservation
On peut exprimer la formule (2.1) différemment de façon à
obtenir la réservation nécessaire pour un délai donné :
| R · |
æ
ç
ç
è |
D - |
|
Di |
ö
÷
÷
ø |
=
(p-R) · |
|
+ L + |
|
Ci |
| R · |
æ
ç
ç
è |
D - |
|
Di |
ö
÷
÷
ø |
= p · |
|
- R · |
|
+ L + |
|
Ci |
| R · |
æ
ç
ç
è |
D - |
|
Di + |
|
|
ö
÷
÷
ø |
=
p · |
|
+ L + |
|
Ci |
Calcul des tampons
De plus, le segment EF représente la quantité maximum de données en attente
de traitement, donc la taille maximum des tampons nécessaires pour éviter
toute perte de paquet. Trois situations sont possibles en fonction des
positions relatives des points A et B et des valeurs relatives de p et R
comme le montre la figure 2.6.
Figure 2.6 : Les trois situations pour le calcul des tampons
Tenant compte de ces trois cas, le calcul de sa longueur (que nous ne
détaillerons pas ici) nous amène à :
|
B = L + |
|
· |
(b-L)
+ |
|
|
æ
ç
ç
è |
|
+ Di |
ö
÷
÷
ø |
X
(2.4) |
avec
| X =
|
ì
ï
ï
ï
í
ï
ï
ï
î |
| r |
si |
|
|
(cas 1) |
| R |
si |
| |
|
> |
|
|
æ
ç
ç
è |
|
+
Di |
ö
÷
÷
ø |
et |
|
p > R |
(cas 2) |
| p |
sinon |
|
|
(cas 3) |
|
|
Notons que ceci est valable pour un flot respectant son TSPEC. Or, les noeuds successifs traversés peuvent avoir pour effet d'augmenter la taille des
rafales, auquel cas des tampons de taille supérieure seront nécessaires.
Ceci est prévu par la spécification de GS [SPG97] qui propose
également de re-lisser le trafic à certains noeuds (reshaping
points) pour limiter l'accroissement de la taille des tampons.
Liaison délai-débit
Il est intéressant de noter qu'avec ce type d'approche, délai et réservation
de bande passante sont couplés. C'est une propriété qui peut poser quelques
problèmes car elle implique qu'on ait besoin d'une forte réservation pour
garantir un délai faible, même si le débit du flot concerné est très
faible. Dans le chapitre 4, section 4.5, nous
proposons une approche possible, basée sur l'agrégation, pour réduire ce
problème.
La technique d'ordonnancement ``Delay-EDD'' (Earliest-Due-Date)
[FV90] permet de fournir des garanties de délai et de bande
passante complètement découplées. Cependant elle nécessite une réservation
au débit crête. Cette technique utilise l'ordonnancement EDD dans lequel les
paquets sont servis dans l'ordre des deadlines qui leur sont
assignées, et spécifie deux autres mécanismes :
-
le contrôle d'admission vérifie que la somme des débits crêtes de
tous les flots ne dépasse pas la capacité du lien,
- la deadline d'un paquet est assignée à la date à laquelle il
serait émis si la source respectait son contrat de trafic (débit
crête). Cela revient à mettre en oeuvre un lissage du trafic quand
nécessaire (i.e. quand il y a contention entre les flots).
L'implémentation est comparable à celle d'un weighted fair queuing
(voir section suivante) car il faut gérer des estampilles par flot. La
complexité liée au calcul du temps virtuel est cependant absente.
2.5 La discipline de service Weighted Fair Queuing
La discipline de service à ``partage équitable pondéré'' (weighted
fair queuing souvent noté WFQ) a suscité beaucoup de travaux depuis de
nombreuses années. La raison de sa popularité tient sans aucun doute à sa
flexibilité : elle peut être utilisée pour le contrôle de congestion (par
partage équitable de la bande passante entre tous les flots), pour fournir
des garanties de débit, de délai (comme nous le montrons en
2.4), pour faire du partage de lien (entre organisations,
classes de trafic etc) et, pour finir, elle peut combiner (de façon plus ou
moins efficace selon les variantes) toutes ces fonctionnalités de manière
hiérarchique pour un modèle à intégration de service complet, comme illustré
figure 2.7.
Figure 2.7 : Modèle à intégration de service hiérarchique
Dans cet exemple, un lien est partagé entre trois organisations A, B et C
qui subdivisent elles-mêmes leur part. L'organisation A utilise des
applications temps réel et alloue donc des parts de bande passante
individuellement à ses flots GS, le reste du trafic étant traité comme un
seul flot. L'organisation B traite séparément ses trafics TCP et UDP (afin
d'empêcher les flots UDP d'accaparer toute la bande passante) et partage à
nouveau la bande passante entre différents types d'applications utilisant
TCP. L'organisation C se contente de séparer son trafic en trois classes
d'applications. Ce type de modèle est proposé par exemple dans
[FJ95].
2.5.1 Fair Queuing
La discipline à ``partage équitable'' (fair queuing) est basée sur
une idée proposée par Nagle [Nag87] pour mettre en place un contrôle
de congestion dans les noeuds du réseau. Considérant qu'avec les
disciplines de service classiques FCFS11,
la meilleure stratégie individuelle pour chaque source (envoyer le plus de
données possible pour utiliser plus de bande passante) est très mauvaise
pour le réseau dans son ensemble (c'est à dire qu'elle crée de la
congestion), Naggle proposait de servir les paquets de chaque source en
tourniquet (round robin). De cette façon, la meilleure stratégie pour
une source n'est plus de transmettre le plus possible mais de consommer
exactement sa part équitable de bande passante. Si une source
transmet plus que ce que l'ordonnanceur lui fournit, ses délais vont
augmenter, puis elle va perdre des paquets. De plus, cela n'a aucune
influence sur le service fourni aux autres sources, ce mécanisme assurant
l'isolation entre les sources.
Un défaut de l'algorithme de Nagle est que l'équité est définie en nombre de
paquets et non en quantité de données. Les sources utilisant des paquets de
grande taille sont donc favorisées. C'est à partir de cette constatation que
Demers et al ont proposé un mécanisme émulant un tourniquet bit à
bit, nommé fair queuing [DKS89]. La version pondérée de
cet algorithme (WFQ pour weighted fair queuing) a plus tard été
réinventée sous le nom PGPS par Parekh et Gallager qui ont prouvé un certain
nombre de propriétés intéressantes. Comme WFQ et PGPS sont le même
algorithme, nous reportons la description de l'algorithme au paragraphe
consacré à PGPS (2.5.3).
2.5.2 Generalized Processor Sharing
Dans [PG93], Parekh et Gallager définissent la discipline de
service Generalized Processor Sharing (GPS), un modèle théorique de
multiplexage de flots (ou sessions) de la façon suivante.
Un serveur GPS conserve le travail et opère à un débit fixé C. Il est
caractérisé par des nombres réels positifs f1, f2, ... fN.
Soit Si(t, t) la quantité de service reçue par la session i dans
l'intervalle de temps [t, t]. Le serveur GPS est défini tel que
pour toutes les sessions i actives (i.e. qui ont du trafic en attente) sur
tout l'intervalle [t, t]. En sommant
Si(t,t) · fj ³ fi · Sj(t,t)
pour tous les j on obtient
Si(t,t) · åfj ³ fi · åSj(t,t)
En conséquence, une part de la bande passante est garantie à la session i
:
Si l'on assure que åj fj £ 1 (par exemple par un contrôle
d'admission), cette garantie s'exprime alors en terme de bande passante
absolue.
GPS est une discipline idéalisée qui suppose que le serveur peut servir
plusieurs sessions simultanément. Il est important de noter que si cela
permet de qualifier ce modèle de ``fluide'', il manipule cependant des
paquets. En particulier le temps de traversé du serveur par un paquet de
taille L appartenant à la session i est égal à sa taille divisée par la
bande passante allouée à la session i, soit son délai de
paquetisation L/Bi.
2.5.3 Packet by Packet GPS et variantes
PGPS - WFQ
Parekh et Gallager proposent une émulation de GPS pour des réseaux réels,
qui ne peuvent transmettre qu'un paquet à la fois. Ils l'appellent PGPS pour
packet by packet GPS. L'idée est de servir les paquets en les triant
sur leur date de fin de transmission sous GPS, c'est à dire que les
paquets seront émis dans l'ordre où ils finissent (et non pas commencent)
leur transmission avec un serveur GPS.
Ils montrent que le retard de service d'un paquet p sous PGPS par rapport
à GPS est borné par le temps de transmission d'un paquet de taille maximum :
Il s'agit donc de trier les paquets avec une estampille correspondant à la
date de leur fin de transmission en GPS exprimée en ``temps
virtuel''. Ce ``temps virtuel'' V(t) est défini de façon que le service
fourni à un flot actif soit constant dans le référentiel de ce temps
virtuel. Cela signifie par exemple que si tous les flots sont actifs, le
temps virtuel progresse à la même vitesse que le temps réel ; si la moitié
seulement des flots sont actifs, ils recoivent un service double, le temps
virtuel progresse deux fois plus vite que le temps réel et le service en
temps virtuel reste donc constant.
Posons que le kieme paquet de la session i arrive au temps
aik et a pour taille Lik. Appelons Sik et Fik les dates
respectives en temps virtuel auxquelles le paquet commence et termine son
service avec le serveur GPS (Fi0 étant initialisé à zéro), on a :
Sik = max ( Fik-1, V(aik) )
L'opération max pour le Sik assure que le paquet ne commence pas son
service avant que le paquet précédent du même flot n'ait terminé sa
transmission (auquel cas le serveur GPS traiterait simultanément deux
paquets du même flot). Le calcul du temps virtuel V(aik) pose un
problème de complexité car il doit être calculé pour chaque paquet et
son calcul est assez complexe à cause des ``effacements en cascade''
(iterated deletions) [Kes97, page 242]. Il existe
cependant d'autres méthodes de calcul (ou plutôt d'approximation) que
nous décrivons plus bas.
Comme nous l'avons dit précédemment, il se trouve que PGPS et WFQ sont le
même algorithme approximant le GPS. Les auteurs du WFQ le concevaient comme
une émulation d'un tourniquet bit à bit, aussi la notion de temps virtuel
est remplacée par le numéro du cycle de service (à chaque cycle un bit est
servi pour chaque session active). D'autres approximations du GPS existent,
nous en décrivons quelques unes dans la suite.
SCFQ
Self-Clocked Fair Queuing [Gol94] résout le problème de
complexité du calcul du temps virtuel en fixant sa valeur à l'estampille
(c'est à dire le temps de fin de service sous GPS) du paquet en cours
de service. L'approximation du GPS est cependant moins bonne que WFQ, les
bornes de délai étant notablement augmentées.
WF2Q
Dans [BZ96b] Bennett et Zhang proposent Worst-case Fair
Weighted Fair Queuing (WF2Q), une émulation de GPS meilleure que PGPS.
Ils montrent en effet qu'avec PGPS, si le retard de service par rapport à
GPS est borné, l'avance de service, elle, ne l'est pas. Parekh et
Gallager cherchaient à montrer les garanties de délais que l'on pouvait
obtenir avec PGPS, ils ne se sont donc pas soucié de cet aspect.
WF2Q borne aussi bien l'avance que le retard de service par rapport à
GPS. Bennett et Zhang définissent un ``indice de pire équité''
(worst-case-fair index) permettant d'exprimer quantitativement le
degré d'équité d'une approximation du GPS.
Une variante, appelée WF2Q+ [BZ96a] est adaptée au cas des
serveurs à capacité variable (voir ci-dessous).
SFQ
Dans le start-time fair queuing [GVC96], les paquets sont
triés par temps de début et non pas de fin de service (Sik). Le temps
virtuel est approximé par le Sik du paquet en cours de service. En plus
d'avoir la même complexité que SCFQ, SFQ fournit des garanties de délais
plus faibles pour les flots à faible débit. Il se comporte de plus
correctement en cas de variation de la capacité du serveur (débit du lien en
sortie) ce qui est nécessaire dans le cas d'un modèle de service
hiérarchique (ou pour des liens sans fil dont la capacité est fortement
susceptible de varier). Notons que ce n'est pas le cas de l'algorithme
original PGPS/WFQ qui n'émule pas correctement un serveur GPS à débit
variable.
VC
Virtual Clock [Zha90] n'émule pas le GPS mais le TDM
(time division multiplexing). L'algorithme est semblable à celui des
fair queuing, la fonction de temps virtuel étant ici remplacée par
le temps réel. Si cette discipline ne fournit pas un partage équitable de la
bande passante, elle présente par contre les mêmes propriétés pour les
garanties de délai que WFQ [FP95], sans la complexité liée au
calcul du temps virtuel.
2.5.4 Évaluation des algorithmes du type fair queuing
Nous avons vu dans les paragraphes précédents différents algorithmes
d'approximation du GPS. L'évaluation de ces algorithmes peut se faire selon
les critères suivants :
-
complexité d'implémentation,
- qualité de l'approximation en terme d'équité,
- qualité de l'approximation en terme de délais,
- comportement avec un serveur à débit variable,
- adéquation à une implémentation matérielle.
Les critères décisifs seront fonction de l'utilisation recherchée.
2.6 Conclusion du chapitre
Depuis de nombreuses années que des recherches sont faites sur la qualité de
service dans les réseaux à commutation de paquets, beaucoup de progrès ont
été faits. Comme nous l'avons montré, on connaît maintenant assez bien les
mécanismes à mettre en place dans le plan de données pour fournir les
garanties dont ont besoin les applications de type temps réel ou multimédias
; garanties de bande passante, garanties de délai.
En ce qui concerne le plan de contrôle, RSVP semble arriver à maturité et
des implémentations sont désormais disponibles. En somme, l'ensemble des
éléments nécessaires à la gestion de la qualité de service dans les réseaux
à commutation de paquets sont désormais assez bien connus.
Cependant, l'évolution des réseaux vers le haut débit apporte de nouveaux
problèmes liés aux technologies utilisées et aux contraintes spécifiques
d'un environnement haut débit. Les mécanismes et modèles que nous avons
décrits ont été conçus essentiellement dans le contexte de réseaux
classiques et ne prennent donc pas en compte ces contraintes (même si
DiffServ tente de résoudre le problème de scalabilité).
La transposition et l'adaptation de ces mécanismes dans le contexte de ces
réseaux haut débit soulève un certain nombre de problèmes. Sont à prendre en
compte d'une part les technologies particulières mises en oeuvre et les
contraintes spécifiques au haut débit, d'autre part les problèmes liés au
facteur d'échelle.
- 1
- La viabilité du service dépend cependant dans une
très large mesure d'un contrôle de congestion géré de bout en bout et mis en
oeuvre par le protocole TCP.
- 2
- Internet Engineering Task
force
- 3
- http://www.ietf.org/html.charters/intserv-charter.html
- 4
- Integrated
Services over Specific Link Layers
http://www.ietf.org/html.charters/issll-charter.html.
- 5
- On distingue le seau de jetons, qui est un modèle de
caractérisation de trafic, du régulateur seau percé (leaky
bucket regulator) qui est un régulateur de trafic constitué d'un seau de
jetons et de tampons mémoire [Kes97].
- 6
- L'intérêt de ce paramètre est de permettre au réseau
d'estimer raisonnablement les ressources par paquet nécessaires pour
le traitement des paquets du flot et d'avoir une limite supérieure sur
l'overhead créé par les en-têtes de niveau liaison.
- 7
- http://www.ietf.org/html.charters/rsvp-charter.html
- 8
- http://www.ietf.org/html.charters/rap-charter.html
- 9
- http://www.ietf.org/html.charters/diffserv-charter.html
- 10
- Par exemple, le délai de paquetisation
d'un noeud émulant le GPS (voir 2.5.2) ou le délai de
réassemblage d'un paquet IP segmenté en cellules ATM.
- 11
- First Come, First Served